[ZOL汽车用品]有这样一句话笔者比较认同——开车,停车难,不开车,出行难。买车,对于大多数人来说,都不是一个重大的负担了,养车,也都是量力而行。唯独停车这事儿,每个人都是心有余而力不足。其实,停车难是一个世界性的问题,外国的月亮也有不那么圆的时候。要不然,也不会有《天天抢车位?这项技术让停车难成为过去》一文中为了停车大费周章的设备,这不,谷歌大大有坐不住了,在近日安卓设备的更新中,为谷歌地图新增了一项功能——预测目的地的停车状况。

谷歌大大是如何做到的呢?
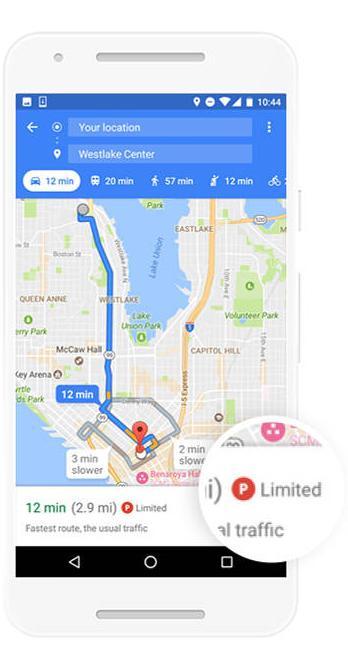
用户只需在谷歌地图中查询路线,就可以看到一个新的图标。如果谷歌预测到你所去的目的地可能有停车难的风险,你就会看到地图上出现一个彩色的点,且附带字母P。停车的难易程度将分为“车位有限”、“中等”和“容易”三个等级。这一功能目前已经向25个美国最大的城市地区开放。谷歌公司正寻求在未来将该功能推广至更多的城市和国家,以及打破平台限制,延伸至苹果iPhone设备上的谷歌地图应用。有时候,网友也会调侃道在iOS平台有两个软件开发商最为良心:一是微软,二是谷歌。

三巨头真是相爱相杀啊!
为什么一个小小的停车难会困扰全世界呢?停车,从以往的经验来说,是不可预测的。停车时,汽车的功能处于休眠状态,数据无法被获取,而且还有一个神奇的现象叫做非法停车。此外,人们的出行计划,停靠时间都是具有很大的随机性。无法预测就是需要实时监控,实时监控又意味着巨大的数据量。这,是一个悖论。
停车标志
谷歌的解决思路分为三个层次:先通过众包的方法获得地面实况数据,然后进入合适的机器学习模型以及训练模型的强大特征集,最终输出产品层面的用户体验,也就是我们前文提到的提车信息反馈和路线规划。
地面实况数据
在机器学习解决方案中,收集高质量的实况数据一直是个关键挑战。即便是谷歌,也经历了一个艰难的过程,他们发现不同的人对“难”的判断是取决于主观而非客观,因此,他们需要给难找到一个衡量标准:时间。“多久能找到停车位?”这样的客观问题,答案的可信度就有了很大的提高,从而能众包产生高质量的、超过10万个回答的实况数据集。
地面实时路况
模型特征
数据不等于特征,数据存在一个拆解重构的过程。大数据分析有一个有别于以往逻辑思维的显著特征——因果关系并不是最重要,事物之间的非必然联系反而成为问题的关键。比如以下情况,每一种都不是因果关系可以处理的:
如果有人在自己门前或者私人的停车位停车,系统不该错误地认为这里的停车位是可用的;用户搭乘出租车到达,可能会造成门前停车很多的假象;公共交通用户可能会被系统认为是在公交车站停车。
让我们换一个思路:
我们来回找一些聚合特征。比如,谷歌所在的Mountain View地区,如果谷歌导航发现大量用户在午餐时间开着车在市中心绕圈,这就表明停车位很难找。顺着这个思路,研究员把用户直接到达目的地时间与绕圈、停车、步行这样实际到达目的地的时间进行了对比,聚合了二者之间的不同。如果多数用户在二者之间所用的时间存在显著差异,就被认为是遇到了停车难的问题。
特定的目的地、散步的停车地点、停车的时间点与日期(例如,用户在早晨会停得离目的地很近,在高峰时间会很远,这怎么办?)、历史停车数据等等。最后,他们得到了大约20个不同的特征。
模型提炼
针对上述特征,研究员使用了一个标准的回归机器学习模型。这种选择有几个原因:首先,逻辑回归的原理是大家所熟知的,并且,在训练数据中,它对噪音是有弹性的;第二,可以将这些模型的输出解释为停车难的概率,然后可以将其映射成描述性术语,如“停车位有限”或“轻松停车”;第三,很容易理解每个特定特征的影响,这使得验证模型是否合理更加容易。例如,当研究员开始训练时,许多人认为上述“蛛丝马迹”的功能将是最好的方法,可以解决所遇到的难题。但实际情况并非如此,事实上,基于车位位置分散的特征才是停车难度最强大的预测因素之一。
编辑点评:停车难的问题,全世界都存在,我们也没有必要去苛求有关部门迅速解决,因为牵涉的利益太广,我们都需要为问题解决出一份力。只是笔者很反对那些借此发不义之财、怠政懒惰和讹人的行为。
推荐相关阅读:
更多汽车用品资讯请关注车品达人公众号或加入ZOL车品QQ群

别说话,扫我
本文属于原创文章,如若转载,请注明来源:天天抢车位?谷歌实况数据终结停车难 //gps.zol.com.cn/626/6260213.html
推荐经销商